一、蓝图
二、准备工作
(一)邮件推送服务
1. 自建方案
夜梦星尘の折腾日记邮局系列教程 | 使用poste.io部署自己的邮局 – 夜梦星尘の折腾日记
邮局系列教程 | 使用poste.io部署自己的邮局 – 夜梦星尘の折腾日记
Posteio 是一个轻量级的开源邮件服务器程序,旨在简化邮件系统的部署和管理。它支持常见的邮件协议(如 SMTP 和 IMAP),并具有内置的反垃圾邮件、反病毒功能,确保邮件通信的安全性和稳定性。Posteio 易于安装,支持 Docker 容器化部署,非常适合中小型企业和个人用户使用,既能够满足基本的邮件发送与接收需求,又能够通过扩展自定义功能来提升系统的灵活性。
2. 直接调用 SMTP
- QQ 邮箱
- 网易邮箱
3. 云服务方案

邮件推送简介_邮件推送购买指南_邮件推送操作指南-腾讯云
腾讯云邮件推送文档主要包含:邮件推送简介、邮件推送购买指南、邮件推送操作指南、邮件推送入门、邮件推送常见问题、邮件推送实践教程…
- 发信域名配置

- 发信地址配置
- 发信模版配置
- 开始发信
- 选择过审的模板,手写 Json 数据替换模板变量,发信成功则可开始构建代码调用。

(二)数据抓取目标
1. 数据来源
- PubMed(权威)
- 骨科、最近一年、按日期从近到远、第一页的网页内容(邮件每日推送,日期很重要,同时也要和数据库历史数据进行比对)
- PMC(PubMed 的公开子集,可以获取到文献全文及其 PDF)
- 骨科、最近一年、按日期从近到远、第一页的网页内容
- GoogleSholar(不太好用)
q=orthopedics:这是搜索查询本身。你可以将其更改为任何你想要搜索的术语,例如q=cardiology。你还可以使用高级搜索语法,如author:"john smith"来搜索特定作者,或者用引号将短语括起来,如"A History of the China Sea",以搜索确切的短语。hl=en:这表示界面语言为英语(English)。你可以将其更改为其他语言代码,例如zh-CN代表简体中文。scisbd=1:这是一个过滤器,它将结果限制在过去一年内发表的论文,并按日期排序。as_sdt=0,5:这是一个更复杂的过滤器。0通常表示不包括专利,而7表示包括专利。
- ……(以后再加再维护)
- SciOpen
- arXiv

2. 附加功能
- 支持定制不同「关键词」,替换 orthopedics;
- 支持对数据来源网站列表做 CRUD。
(三)VPS、n8n 及其工具 API key
1. 一台崭新的 VPS
- VPS 一是部署 n8n 和邮件服务等后端程序,二是后续时间充沛可以自己完成网页解析,脱离 n8n。

2. n8n+后端服务
- n8n 文档
n8n_ion8n.io - AI workflow automation tool
n8n.io - AI workflow automation tool
n8n is a free and source-available workflow automation tool

欢迎来到 n8n 中文教程 | 简单易懂的现代魔法 - n8n 中文使用教程欢迎来到 n8n 中文教程 | 简单易懂的现代魔法 - n8n 中文使用教程
欢迎来到 n8n 中文教程 | 简单易懂的现代魔法 - n8n 中文使用教程
知识库首页

- 需配置密钥的服务
Firecrawl - The Web Data API for AIFirecrawl - The Web Data API for AI
Firecrawl - The Web Data API for AI
The web crawling, scraping, and search API for AI. Built for scale. Firecrawl delivers the entire internet to AI agents and builders. Clean, structured, and ready to reason with.

首次调用 API | DeepSeek API Docs
首次调用 API | DeepSeek API Docs
DeepSeek API 使用与 OpenAI 兼容的 API 格式,通过修改配置,您可以使用 OpenAI SDK 来访问 DeepSeek API,或使用与 OpenAI API 兼容的软件。

PostgreSQLPostgreSQL
PostgreSQL
The world's most advanced open source database.

三、开始构建
(一)n8n 定时提取网页中数据
1. 定时任务触发
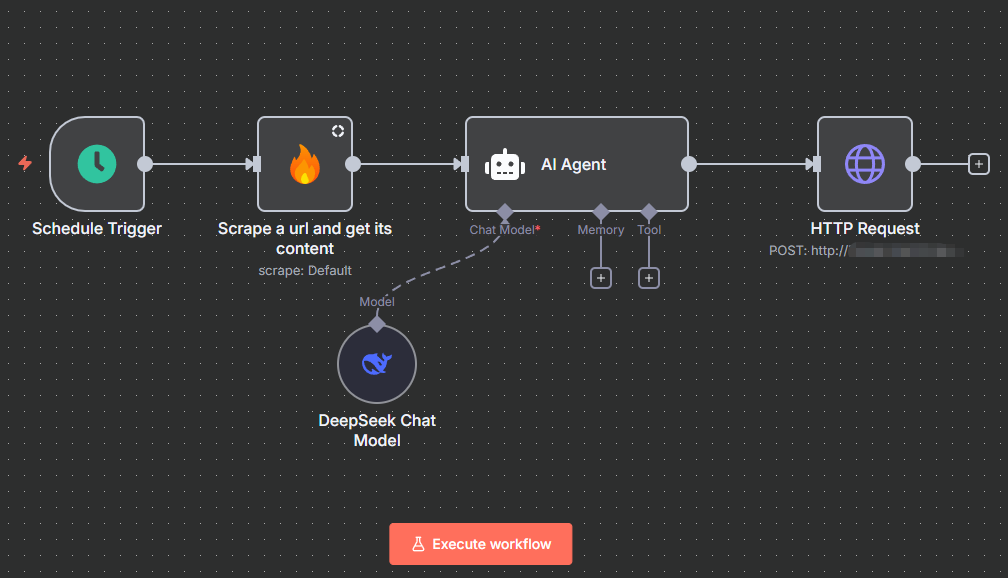
- 新建一个工作流,修改该工作流设置中的时区,并添加定时任务触发节点作为起始点——如上海时间每天早上八点,激活后此工作流将定时开始运行。


2. Firecrawl 抓取目标网页内容
- n8n 中的 Firecrawl 有七种功能(20250904),因为之前已经准备了带查询参数的目标网页 URL,所以直接开始用 【Scrape a url and get its content】 即可。
- Search and optionally scrape search results (搜索并抓取搜索结果)
- 功能: 在搜索引擎上执行搜索,并可以选择性地抓取搜索结果页面上的数据。
- 适用场景: 需要从搜索引擎结果中快速收集信息,比如进行市场调研、关键词分析或监控竞争对手的排名。
- Map a website and get urls (映射网站并获取 URL)
- 功能: 扫描一个网站并生成一个完整的URL列表,就像创建一张网站地图。
- 适用场景: 在进行网站审计、SEO分析时非常有用,可以快速了解网站的整体结构和所有页面。
- Scrape a url and get its content (抓取 URL 并获取内容)
- 功能: 抓取单个网页的内容,并将其转换为结构化的数据,如文本或Markdown。
- 适用场景: 从单个网页上提取特定信息,例如获取一篇博客文章、一个产品描述或一个新闻报道的内容。
- Crawl a website (爬取网站)
- 功能: 递归地抓取整个网站,自动跟随链接,获取多个页面上的数据。
- 适用场景: 当你需要从整个网站上收集大量数据时,比如建立一个内容数据库、进行大规模的数据分析或创建自己的搜索引擎索引。
- Get crawl status (获取爬取状态)
- 功能: 查看正在进行的网站爬取任务的进度和状态。
- 适用场景: 监控大型爬取任务,确保任务顺利进行,并在出现错误时及时排查。
- Extract Data (提取数据)
- 功能: 从爬取到的内容中提取特定类型的数据,通常需要定义好数据的提取规则。
- 适用场景: 从非结构化的文本中提取结构化信息,比如从产品页面中提取价格、名称和评论,或从简历中提取联系方式和工作经历。
- Get Extract Status (获取提取状态)
- 功能: 检查数据提取任务的进度和结果。
- 适用场景: 监控数据提取过程,确保所有目标数据都被正确地提取出来。

- 测试直接抓取,成功返回数据。

- 使用 Agent 提取数据并整理为需要的格式。

(二)n8n 向数据库保存结构化数据
1. 初始化数据表
- 原生 sql 实现
- ORM 实现
2. 连接、查看数据表
- 确认创建成功


3. 把 Agent 输出的邮件内容持久化存储到 postgreSQL 数据库
- 根据文本哈希值去重,避免重复新增相同内容
- 保存

(三)腾讯云邮件推送服务接口开发与部署
- 使用 FastAPI 调用腾讯云邮件推送服务
- SMTP 直接发送
- n8n 通过 HTTP 节点调用 FastAPI 推送邮件

- Author:沈林曦
- URL:https://aibhtt.com//article/n8n-post-email
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!